

Introduction
Huge Language Models (HLMs) have revolutionized language understanding and generation. They have found applications across different fields, including finance and healthcare. Nonetheless, the advancement of language models faces challenges due to data scarcity. Moreover, privacy is required in handling private domain data. To address these challenges, The emergence of Federated Learning (FL) as a promising technology that allows for collaborative training while maintaining decentralized data. Federated LLM Fine-tuning, as well as Engineering prompts for Federated LLM. We explore the advantages of these elements compared to conventional LLM training techniques. Furthermore, we also explore potential methods for integrating FL and LLM while addressing the associated challenges.
Background
A. Federated Learning
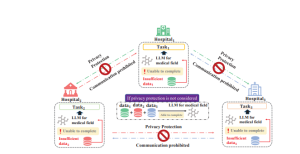
In Federated Learning, machine learning is done collaboratively when many clients join forces to train a model that is used by all supervised by a central server. FL allows data to remain locally held, unlike conventional centralized approaches, ensuring privacy and reducing privacy risks and costs. By keeping data secure and private, this decentralized approach, and decreasing the likelihood of privacy breaches as well as any related costs. Secure collaboration in FL is made possible through the development of secure aggregation methods based on Secure Multi-Party Computation (SMPC) and techniques like Federated Averaging (FedAvg). Privacy-sensitive fields like healthcare have seen the effectiveness of FL. It allows multiple parties to cooperate without directly revealing their sensitive data.
B. Large Language Models
LLMs are large-scale language models built upon pre-trained language models (PLMs). Pre-training involves training a base model on unlabeled text from a large corpus to acquire general language knowledge. After pre-training, the model is adjusted for a particular task with labeled data to improve its performance. By fine-tuning, the model is adapted for specific tasks or domains using labeled data. Prompt techniques in engineering enhance model effectiveness by developing compelling prompts for user interactions. Impressive abilities have been demonstrated by LLMs and find extensive application in challenging tasks because of their substantial size and extensive training data.
Federated LLM
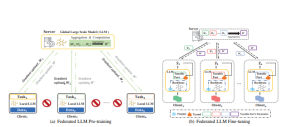
Classic LLMs face challenges because of a lack of high-quality public domain data. This is addressed by Federated LLM Pre-training by combining decentralized private data sources and centralized public data. The generalization of models is enhanced with this approach while ensuring the security of data. Two approaches are proposed: one requires client-level data preprocessing and task design, enabling customizable model checkpoints. Another approach involves using pre-existing base models and optimizes them further, thus minimizing computational burden. LLM Pre-training with Federated approach builds a base for scalable models, promoting enhanced data utilization and performance.
B. Federated LLM Fine-tuning
Conventional LLM fine-tuning faces challenges due to inter-institutional collaboration barriers and potential data mismatches. Collaborative Fine-tuning of LLM fosters collaboration by using supervised data from multiple clients for joint multi-task training. Models that have been fine-tuned get distributed to clients, enhancing model generalization. Two approaches are proposed: direct full-model fine-tuning for superior performance but with increased expenses. Fine-tuning based on federated learning with efficient parameter methods is recommended to optimize both performance and efficiency. LLM Fine-tuning in a federated manner allows efficient collaboration while preserving model flexibility.
C. Federated LLM Prompt Engineering
The traditional approach to prompt engineering depends on data that is available to the public, limiting model adaptability and leading to repetitive responses. LLM Prompt Engineering with Federated Approach combines FL and prompt engineering for creating prompt templates using sensitive data. Users have the option to upload prompt learner parameters that have been updated locally, minimizing the risks associated with transmitting raw data. This approach boosts the model’s ability to learn in context. It effectively deals with intricate tasks and provides personalized prompts tailored to client requirements.
Conclusion
Distributed Large Language Models present a potential solution to the challenges faced in training LLMs. Through the integration of FL and LLM training, the privacy of data can be upheld. Institutions can facilitate collaboration, and Performance of the model can be optimized. Federated LLM consists of three components—Pre—training, Fine-tuning, and Prompt Engineering—offer effective approaches for advancing the development and application of large-scale language models in environments that prioritize privacy. As technology continues to progress, additional exploration and advancement in Federated LLM hold immense potential for reshaping the landscape of language processing and collaborative training. Nonetheless, it is essential to guarantee that privacy and security worries are dealt with to fully utilize the benefits of this strategy.


