

Introduction
Reinforcement Learning (RL) has emerged as a powerful framework for training models to improve performance by learning from their own mistakes. However, RL agents often struggle to generalize learned policies to handle new tasks or environments. This limitation has sparked interest in Meta-Reinforcement Learning (Meta-RL), which aims to enable models to adapt and generalize to previously unseen challenges. In this article, we will dive into the world of Meta-RL, its applications, and key components that make it an exciting prospect in building artificial intelligence with broader problem-solving capabilities.
Understanding Meta-Reinforcement Learning
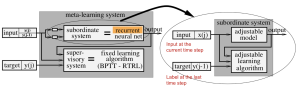
At its core, Meta-RL is an extension of Meta-Learning applied to the domain of Reinforcement Learning. It focuses on training models to not only excel in solving specific tasks but also adapt to new and diverse problems. A key advantage of Meta-RL lies in its ability to autonomously adjust internal states to tackle novel environments without explicit fine-tuning.
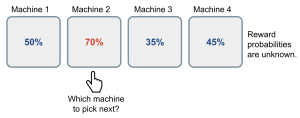
A Simple Experiment: The Multi-Armed Bandit Problem
To comprehend the concept of Meta-RL, let’s consider the classic multi-armed bandit problem. Imagine being in a room with two levers, each with a different probability of yielding a reward. The challenge is to choose the lever with the highest reward probability. Traditional RL methods might struggle with changing probabilities, but a Meta-RL agent can quickly adapt to new probability values and make informed decisions.
Components of Meta-Reinforcement Learning
- Model with Memory: Memory is crucial for Meta-RL models to acquire and store knowledge from the environment, helping them update their hidden states. Recurrent Neural Networks (RNNs), such as LSTMs, are commonly used to maintain the hidden state of Meta-RL models.
- Meta-Learning Algorithm: The meta-learning algorithm determines how the model updates its weights based on previous learning experiences. Techniques like MAML and Reptile effectively optimize the model for solving new tasks with minimal exposure to those tasks.
- Proper Distribution of Markov Decision Processes (MDPs): MDPs represent the environment and the decision-making process of the agent. A diverse distribution of MDPs ensures the Meta-RL agent can adapt swiftly to varying conditions and different tasks. Evolutionary algorithms and unsupervised approaches are utilized to create a collection of tasks and reward functions for the agent to learn from.
Applications and Potential of Meta-RL
Meta-RL has vast applications in developing advanced AI systems capable of adapting to dynamic real-world scenarios. Its ability to handle diverse tasks with limited data points makes it a promising candidate for building intelligent agents for complex problem-solving domains. As research in Meta-RL progresses, we can expect to witness significant advancements in artificial intelligence and the emergence of more robust and adaptable AI systems.
Conclusion
Meta-Reinforcement Learning represents a fascinating frontier in AI research, offering the potential to create intelligent agents that can learn to learn effectively. By combining memory-based models, sophisticated meta-learning algorithms, and diverse MDP distributions, Meta-RL equips AI with the ability to tackle new challenges with agility and competence. As we continue to explore and refine Meta-RL techniques, we move closer to realizing the vision of building artificial brains capable of unprecedented learning and adaptation.


